École Polytechnique
Université de Montréal
Ajout et adaptation d'un algorithme
d'apprentissage (arbre de décisions)
à une librairie (AD)
Projet de fin d'études soumis comme
condition partielle à l'obtention du
Baccalauréat en ingénierie
DÉPARTEMENT DE GÉNIE INFORMATIQUE
15 Avril 1999 Présenté par : Francis Piéraut
Dernière revision: 14 Avril 1999
Le but de l'expérience rapportée ici est d'incorporer et d'adapter un algorithme d'apprentissage (un arbre de décisions) à la librairie AD (Adaptative Decider) du département Labs de Microcell[1]. Actuellement cette librairie permet de faire de la prédiction au moyen d'autres algorithmes d'apprentissage tels les réseaux de neurones. La réalisation de ce projet nécessita une cinquantaine d'heures de recherche et de lectures ainsi que 3 mois et demie pour sa réalisation. Les principaux outils de référence étaient des ouvrages spécialisés, des discussions avec mes confrères de travail, un logiciel existant, des bancs d'essais ainsi que des documents sur internet. La validité des résultats fut confirmée par des comparaisons avec le programme C4.5[2] sur plusieurs bancs d'essais[3]. Ce travail devait être utilisé pour prédire le désabonnement des clients au service FIDO de Microcell[4] et sur différents cas de prédiction.
Mots-clés: Prédiction - Algorithme d'apprentissage - Arbre de décisions - Contrôle de capacité
Table 2 *
Table 3 *
Table 4 *
Table 5 *
Table 6 *
Table 7 *
Table 8 *
Table 9 *
Table 10 *
Table 11 *
Figure 1 *
Figure 3 *
Figure 4 *
Figure 5 *
Figure 6 *
SOMMAIRE *
LISTE DES TABLEAUX *
LISTE DES FIGURES *
REMERCIEMENTS *
SPÉCIFICATIONS ET LIMITES *
LIMITES *
REVUE DE LA DOCUMENTATION *
MÉTHODOLOGIE DE TRAVAIL *
CADRE THÉORIQUE *
Théorie de l'apprentissage *
CONSTRUCTION DE L’ARBRE *
ALGORITHMES *
TRAITEMENT DES ATTRIBUTS CONTINUES *
RÉSULTATS *
EXPÉRIMENTATIONS *
LES STRUCTURES DE DONNÉES ET LES INTERFACES *
L'IMPLANTATION *
CONCLUSION *
RÉFÉRENCES *
J'aimerais exprimer ma reconnaisance à tous ceux qui ont contribué à la réalisation de ce travail: Samy Bengio du Centre interuniversitaire de recherche en analyse des organisations qui m'a supervisé durant la réalisation de ce projet. Les membres de mon équipe de travail, soient : Jean-Francois Isabelle, Simon Drouin, Sébastien Lambert, Réjean Ducharme et Ayman Farhat. Caroline Courtemanche pour le soutient durant la rédaction de ce rapport et mon colocataire, Christian Laforte, avec qui j'ai pu échanger sur de multiples sujets durant les périodes creuses de la rédaction.
Dans bien des domaines il nous est utile de pouvoir faire de la prédiction. Une des solutions consiste à conserver de l'information sur des cas réels et de s'en servir pour prédire de nouveaux cas. Plusieurs algorithmes d'apprentissage nous permettent de trouver des tendances dans les données recueillies. Il existe une théorie sur l'apprentissage qui nous permet de trouver le modèle le plus général possible. En conbinant ces algorithmes et le contrôle de la capacité tel qu'expliqué dans la théorie de l'apprentissage, il est possible de trouver des modèles efficaces de prédiction. La prédiction peut se faire en terme de classification ou en terme de régression. La classification fait référence au fait de prédire une caractéristique discrète tandis que la régression fait référence à la prédiction d'une caractéristique continue. Les différents algorithmes d'apprentissage ont chacun leurs forces. Par exemple les réseaux de neurones permettent souvent de construire un modèle de prédiction plus efficace que les arbres de décisions en classifiaction. Par contre, en ce qui concerne la régression, la rapidité d'exécution et la plus grande facilité d'interprétation, les arbres de décisions semblent meilleurs. Sachant que la librairie AD ne permet pas de faire de la prédiction au moyen d'arbre de décisions et connaissant les forces de ce modèle, il devient interressant d'ajouter cette fonctionnalité. AD est une librairie permettant de faire de la prédiction.
Samy Bengio, directeur de recherche de Microcell Labs, me proposa en Janvier 1998 de me pencher sur la compréhension des arbres de décisions afin de présenter au groupe le fonctionnement de cet algorithme. Par la suite, on me proposa d'implanter cet algorithme et de l'adapter afin qu'il puisse être utilisé dans la libraire AD. Ce projet fut réalisé dans le cadre d'un travail à temps partiel durant la session d'hiver et d'un emploi d'été en 1998 dans le département Labs de Microcell. Samy Bengio et Jean-francois Isabelle m'ont conseillé durant l'adaptation de l'algorithme à la librairie. Jean-Francois Isabelle, Simon Drouin, Sébastien Lambert et Réjean Ducharme m'ont été d'une grande aide durant la partie "débuggage". L'objectif était de pouvoir se servir des arbres de décisions en régression dû à la force de cet algorithme dans ce domaine et de le comparer en terme de classification aux réseaux de neurones dans la prédiction du désabonnment au service FIDO.
Les arbres de décisions sont une famille d'algorithmes d'apprentissage non-paramétriques introduits dans les années 80. Dans un arbre, chaque noeud est ou bien une feuille dénotant une décision ou bien une branche spécifiant un test sur une valeur d'un attribut. Le nombre de descendants de chaque noeud dépend des résultats du test effectué à ce niveau. Un arbre de décisions peut être utilisé pour prendre une décision concernant un nouvel exemple. En effet, en commencant par la racine et en se déplacant à travers les branches, la décision de la feuille terminale satifaisant tous les tests précédants est prise. Un exemple et des explications plus poussées se retrouvent dans les prochaines sections.
Cette implantation devrait nous permettre d'utiliser des arbres de décisions au même titre que tout autre algorithme d'apprentissage sans modification des entrées et sorties telles qu'utilisées dans la librairie AD. Cette spécification nous oblige à avoir une structure objet afin de réutiliser les fonctions d'entrée et sortie et d'implanter tout ce qui concerne la construction du modèle et son interprétation à partir des arbres de décisions. Les structures d'entrées et de sortie doivent être compatibles. Sachant que l'implantation des arbres de décisions en terme de classification devait être complétée pour la fin août 98, nous devions trouver la solution la plus efficace. C'est pourquoi nous avons tout d'abord regardé certaines implantations des arbres de décisions afin de les réutiliser. Parmi les algorithmes d'arbre de décisions les plus connus, on retrouve ID3 et C4.5[5] qui ont été conçus principalement pour résoudre les problèmes de classifications. Il existe aussi CART[6] qui utilise des arbres de décisions pour faire de la classification et de la régression. Nous nous sommes procurés le code source de C4.5[7] écrit en C. Afin de répondre aux spécifications, il aurait été nécessaire de modifier presque tout le code. La structure n'était pas objet, le code n'était pas très bien documenté, les structures d'entrées et de sortie n'étaient pas compatibles et plusieurs options ne nous intéressaient tout simplement pas. Bref, il était plus simple de tout réécrire. La démarche utilisée pour la réalisation de ce projet fut itérative. Nous avons d'abord implanté les arbres de décisions en terme de classification pour les cas discrets puis, un fois testés et conformes à d'autres implantations, nous avons ajouté les cas continus et un paramètre de contrôle de capacité.
AD est une libriairie qui généralise des mécanismes pour faire des expériences tel que les lectures de données, les mesures, les fichiers de résultats, les arrangements sous forme de réseau d’algorithmes d’apprentissage etc. Afin d’utiliser facilement toutes ses fonctionnalités, AD possède aussi un interpréteur de spécifications.
L'implantation de la régression est un cas particulier ainsi qu'une interprétation variée de la classification dans le contexte des arbres de décisions. En classification, la classe prédite pour un nouvel enregistrement sera la plus probable au niveau de la feuille terminale. En régression la valeur prédite sera la moyenne des valeurs de la feuille terminale. Par conséquent, nous nous sommes limités à la classification. Les autres limites importantes de se projet sont : impossibilité de traiter des données ayant des inconnues, seule une méthode de contrôle de capacité est implantée .
C4.5 sera la référence utilisée afin de réaliser ce projet. C4.5 est une implantation d'arbre de décisions faite par J. Ross Quinlam. Nous nous sommes basés sur son livre intitulé "C4.5 : Programs for machine learning"[1] pour comprendre les algorithmes nécessaires à l'implantation. Une fois ces algorithmes compris, nous les avons écris sous forme de pseudo-code. Le programme C4.5 a servi de référence pour vérifier nos résultats.
Le livre "Classification and regression trees"[6] fut le livre consulté pour comprendre la différence en terme d'implantation des arbres de décisions pour la régression et la classification. Ceci nous a permis de nous assurer que la majorité des fonctions soient assez générales pour traiter des cas en classification et en régression.
Notre compréhension de la théorie de l'apprentissage nous a été possible grâce à la présentation de Samy Bengio et nos discussions ainsi que d'un texte écrit par Yoshua Bengio[8]. Ceci nous a permis d'implémenter des fonctions de contrôle de capacité.
Plusieurs textes trouvés sur internet ont servi de complément, voici le plus significatif d'entre eux:
Les notes de cours, APPRENTISSAGE A PARTIR D'EXEMPLES de François Denis Rémi Gilleron de l'Université Charles de Gaulle[9].
Les données qui nous ont permis de faire des tests se trouvent à l'addresse suivante : ftp://ftp.ics.uci.edu/pub/machine-learning-databases/
Stratégie d'implantation utilisée pour la réalisation du projet
La comparaison des résultats consitera à vérifier que les arbres générés par C4.5 et AD sont identiques.
Mise en situation sur la prédiction
Nous possédons un ensemble d'enregistrements. Chaque enregistrements à la même structure formée d'un nombre d'attributs pouvant prendre chacun plusieurs valeurs continues ou discrètes. Un des attributs représente la classe de l'enregistrement. Le problème consiste à déterminer un arbre de décision constitué de questions sur les attributs non-classe qui permettent de prédire la classe de cet enregistrement.
Afin de faire de la prédiction, nous utilisons des algorithmes permettant de construire un modèle de prise de décisions à partir d'un échantillon de données. C'est ce que nous appelons des algorithmes d'apprentissage.
Cette théorie nous donne les concepts nécessaires pour
contrôler la généralité du modèle de prédiction à partir
d'un ensemble de données. Avant de débuter les explications, il
nous est nécessaire de définir certains concepts et symboles
qui seront utilisés dans les explications subséquentes.
| CONCEPTS | DÉFINITIONS |
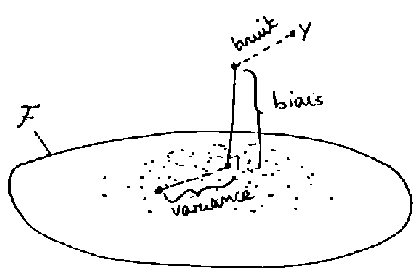
| Le bruit | Dans toutes données, nous retrouvons du bruit car celles-ci sont imparfaites. Ces imperfections proviennent des erreurs de mesures, une étiquette incorrecte etc. Le bruit est une erreur dans les données qui sera toujours présente. |
| Le biais | Le biais est l'écart entre la meilleur solution d'un algorithme d'apprentissage et la solution parfaite. Plus l'ensemble de fonctions est grand, plus le biais sera petit. |
| La variance | La variance est la distance
moyenne entre la fonction trouvée et la meilleure fonction qui aurait pu être trouvée. Plus l'ensemble de fonction est grand, plus le biais et grand. |
Voici une représentation graphique de ces 3 concepts.
| SYMBOLES | |
| Eapp | Erreur d'apprentissage |
| Egen | Erreur de généralisation |
| Egen* | Erreur de généralisation minimum que l'on peut atteindre avec l'algorithme de prédiction |
| Dl | Ensemble de données utilisées pour l'apprentissage. D : données, l : nombres d'éléments. |
| Q(z,f) | Fonction de coût |
| F | F représente une des solutions |
| F | F représente l'ensemble des solutions possibles. |
| Z | Représente la solution à ce que l'on veut prédire |
| X | La prédiction |
| Y |
|
| h(f) | La capacité reliée à la fonction f. |
| h*(f) | La capacité qui engendre l'erreur de généralisation minimum |
| P(Z) | Distribution inconnue |
Afin de bien comprendre la théorie de l'apprentissage, il nous faut d'abord éclaircir la notion de Généralisation:
Le problème de l'induction est de trouver f qui minimise le risque espéré Egen, mais on ne peut le mesurer, seul Eapp est mesurable. Noter que Eapp est une approximation bruitée mais non-biaisée de Egen (pour un f quelconque choisi indépendamment de Dl). Une grande quantité d'algorithmes d'apprentissage ne font que minimiser le risque enpirique afin de trouver une solution. Comme vous le comprendrez avec les explication subséquentes, la solution qui minimise l'erreur d'apprentissage n'est pas celle qui minimise l'erreur de généralisation.
Il est possible de borner la différence entre l'erreur de généralisation et l'erreur d'apprentissage sous certaines conditions. Ces bornes dépendent de ce qu'on appelle la capacité h(f) , qui est une mesure de sa « complexité ». Dans le cas de problèmes de classification, la capacité h(f) est le plus grand l tel que, pour un certain ensemble d'exemples Dl, on peut toujours trouver un f appartenant à F qui donne la bonne réponse sur tous les exemples de Dl, quel que soit l'étiquetage de ces exemples. Sachant que l'erreur de généralisation ne peut être calculée, nous pouvons l'approximer car Eapp est un estimé bruité mais non-biaisé de Egen quand les données servant à calculer Eapp ne sont pas tirées de l'ensemble d'apprentissage. Donc nous avons besoin d'un ensemble d'apprentissage et d' un ensemble de test.
Voici 2 exemples qui nous permettent de voir comment une fonction de coût peut être évaluée dépendemment du contexte:
Ne pouvant pas réduire l'erreur due au bruit intrinsèque, il nous reste un dilemme entre le biais et la variance. Le dilemme biais-variance exprime le conflit entre le désir de réduire l'erreur de biais et celui de réduire l'erreur de variance. Quand on augmente la capacité l'erreur de biais diminue, mais l'erreur de variance augmente.
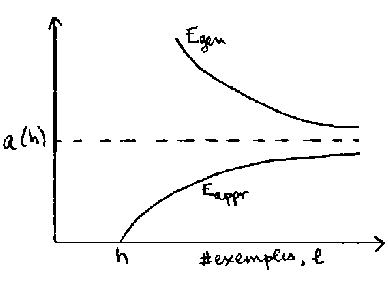
Courbe d'apprentissage (analyse quantitative). Quand le nombre d'exemples l augmente, l'erreur d'apprentissage augmente, et l'erreur de généralisation diminue. Ces deux courbes se rejoignent asymptotiquement à une valeur a(h) qui dépend de la capacité h.
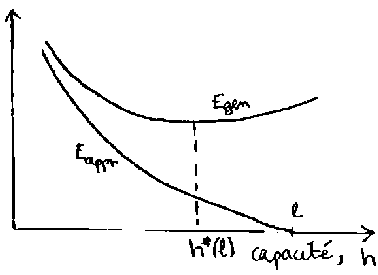
Quand la capacité h(f) augmente, l'erreur d'apprentissage diminue. Quand la capacité h(f) augmente, l'erreur de généralisation commence par diminuer, puis atteint un minimum (à la capacité optimale) et finalement remonte. Donc il faut contrôler la capacité ou le niveau d’apprentissage pour atteindre la meilleur erreur de généralisation.
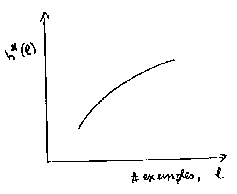
La capacité optimale dépend de l au fur et à mesure que l augmente, la capacité optimale augmente. Plus on a d'exemples, plus on peut se permettre un modèle complexe.
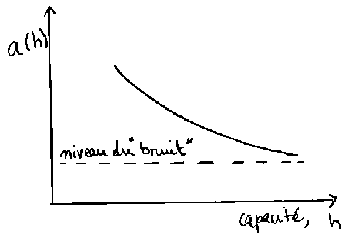
Au fur et à mesure que la capacité h augmente, l'erreur asymptotique a(h) diminue, jusqu'à atteindre le niveau de bruit intrinsèque au problème.
Le contrôle de la capacité peut se faire durant la construction de l'arbre et par élagage après sa construction. La manière dont nous allons procéder pour contrôler la capacité après la construction de l'arbre sera expliquée plus loin. À cette étape, nous allons nous pencher sur la compréhension du modèle de prédiction qu'est l'arbre de décision et la manière dont il est construit. Pour ce faire, nous allons tout d'abord définir ce qu'est un arbre de décisions: un arbre de décisions est une série de questions ordonnées sous forme d'un arbre permettant de prédire la classe d'un enregistrement. Les Classes représentent les différentes valeurs que peut prendre l'attribut que l'on désire prédire. Par exemple, si nous voulons prédire l'accumulation de neige au sol suite à une tempête, les classes pourraient être : «petite accumulation », « accumulation moyenne », « grande accumulation ». Un enregistrement est une série d'attributs pouvant prendre plusieurs valeurs (discrètes ou continues). Les Attributs sont les caractéristiques d'un enregistrement. Les conditions générales sont que nous avons N enregistrements ayant M attributs et que nous voulons prédire l'attribut de la position j (la classe de l'enregistrement) à partir des autres.
Avant d'aller plus loin dans les explications, voici un exemple d'arbre de décisions qui nous permet de prédire si l'on pourra jouer au golf selon les prédictions météorologiques. Cet exemple nous servira de référence pour certaines explications.
PRÉVISION / | \ / | \ nuageux / |ensoleillé \pluvieux / | \ OUI HUMIDITÉ VENTEUX / | | \ / | | \ <=75 / >75| vrai| \faux / | | \ OUI NON NON OUI
Exemple d'utilisation de l'arbre pour faire de la prédiction
Voici les prévisions météorologiques dont nous allons nous servir.
PRÉVISION | TEMPERATURE | HUMIDITÉ | VENTEUX | JOUER |
Ensoleillé | 85 | 85 | faux | Ne pas jouer or JOUER ? |
Selon l'arbre, on ne devait pas jouer car la température extérieure est ensoleillée et l'humidité est supérieure à 75 %.
Voici la terminologie reliée à la structure d’un l’arbre.
| TERMINOLOGIE | DÉFINITION |
| Feuille | Représente la fin de la fragmentation des données. Une décision de classification est rendue à ce niveau. La classe associée à une feuille est celle dont le nombre d'enregistrements de l'échantillon à ce niveau est le plus grand |
| Branche | Une
branche représente le niveau ou les données sont
fragmentées par une question. Unité de base d'un arbre
de décisions. Une branche conserve la répartition des
enregistrements, l'erreur , *la question choisie et *les
branches subséquentes. * Si approprié |
| Noeud | Un noeud est soit une branche, soit une feuille. |
Si nous observons l'arbre de l'exemple précèdent en considérant les explications ci-haut, tous les endroits où nous voyons OUI et NON sont des feuilles. Voici les trois branches de l’arbre :
(1)PRÉVISION :Cette branche est associée à la racine / | \ / | \ nuageux / |ensoleillé \pluvieux / | \ OUI HUMIDITÉ VENTEUX / | | \ / | | \ <=75 / >75| vrai| \faux / | | \ OUI NON NON OUI (2)HUMIDITÉ (3)VENTEUX :Ces deux branches sont des sous branches de la branche(1) / | | \ / | | \ <=75 / >75| vrai| \faux / | | \ OUI NON NON OUI
Voici les données qui nous ont permis de construire l'arbre de décisions qui nous permettait de prédire si l'on pourrait jouer au golf selon les prédictions météorologiques.
ATTRIBUTS | Valeurs possibles |
PRÉVISION | Ensoleillé, Nuageux, Pluvieux |
TEMPERATURE | continu |
HUMYDITÉ | continu |
VENTEUX | vrai, faux |
Les données d'entraînement:
PRÉVISION | TEMPERATURE | HUMIDITÉ | VENTEUX | JOUER |
Ensoleillé | 85 | 85 | faux | Ne pas jouer |
Ensoleillé | 80 | 90 | vrai | Ne pas jouer |
Nuageux | 83 | 78 | faux | Jouer |
Pluvieux | 70 | 96 | faux | Jouer |
Pluvieux | 68 | 80 | faux | Jouer |
Pluvieux | 65 | 70 | vrai | Ne pas jouer |
Nuageux | 64 | 65 | vrai | Jouer |
Ensoleillé | 72 | 95 | faux | Ne pas Jouer |
Ensoleillé | 69 | 70 | faux | Jouer |
Pluvieux | 75 | 80 | faux | Jouer |
Ensoleillé | 75 | 70 | vrai | Jouer |
Nuageux | 72 | 90 | vrai | Jouer |
Nuageux | 81 | 75 | faux | Jouer |
Pluvieux | 71 | 80 | vrai | Ne pas Jouer |
Afin de contrôler la capacité durant la construction de l'arbre il nous faut contrôler l'apprentissage. En effet, n'importe quel test qui fragmente un ensemble en deux ou plusieurs ensembles non vides, va finalement après N répétitions donner des sous ensembles qui contiennent des exemples d'une même classe. La plupart des sous ensembles obtenus contiendront un seul exemple. Une capacité élevée entraîne un erreur de généralisation très grande.
Dans[10], on a montré qu'explorer tous les arbres possibles pour choisir l'arbre optimal est un problème NP-Complet. Dans le cas traité précédemment, la prédiction sur le golf, nous pouvons construire 4 X 10 EXP 6 arbres différents. Tout ceci nous amène à bien comprendre la nécessité d'un critère sur les attributs pour choisir les meilleurs questions afin de contrôler la capacité et de réduire la complexité. Un critère, pour évaluer les tests, fournit un mécanisme pour classer l'ensemble des tests et choisir le meilleur. Cela présume qu'il existe plusieurs façons pour générer les tests possibles. Afin de simplifier le critère, un seul attribut sera impliqué dans le test.
C4-5 contient un mécanisme qui contient 3 types de test :
Le critère nous permettant de choisir la meilleure question est celui qui fragmente le moins possible les enregistrements de même classe à travers ses noeuds. Afin de pouvoir trouver les questions associées aux noeuds qui permettent de minimiser cette fragmentation, il nous faut une manière de quantifier l'information d'un ensemble d'enregistrements afin de pouvoir faire des comparaisons et de choisir la meilleur question. Une fois que nous possédons une méthode pour quantifier l'information, il nous est possible de comparer l'impact des différentes questions sur la fragmentation et de choisir celle qui minimisera celle-ci. Cette méthode consiste à trouver l'attribut qui possède le gain maximum.
ID3 est l'algorithme ancêtre de C4.5.Dans celui-ci, J. Ross Quinlam utilisa la notion de gain afin de choisir l'attribut sur lequel il fera la subdivision des données. Le gain constitue la manière de répondre à la problématique qui consiste à trouver un moyen de choisir l'ordre des questions dans l'arbre. Plusieurs notions sont préalables à la compréhension de cette notion, soient :
| TERMINOLOGIE | Description |
| Info(T) | Quantification de l'information nécessaire pour prédire la classe à partir de l'échantillon T. |
| InfoX(T) | Quantification de l'information nécessaire pour prédire la classe après la fragmentation de l'échantillon T par la question X. Ceci est en fait une moyenne pondérée de l'information nécessaire pour trouver la classe. |
| GainX(T) | Quantification de l'amélioration causée par la fragmentation de l'échantillon T par la question X. |
Le gain est en fait l'information d'un échantillon (Info(T)) moins l'information de l'échantillon suite à la subdivision par une question X (InfoX(T)). En utilisant le gain pour tous les attributs, il nous est possible de trouver l'attribut qui minimisera la perte d'information suite à la subdivision de l'échantillon.
| NOM | EQUATION |
| GainX(T) | Info(T) - InfoX(T) |
| Info(T) | -S Freq(j) * Log2( Freq(j) ) Pour toutes les classes "j" possibles. Où: Freq(j):Probabilité de la classe "j" et Log2(Freq(j) ): Nb de bits pour représenter Freq(j) |
| InfoX(T) | S nb(Ti)/nb(T) * Info(Ti) Pour tous les sous ensembles "Ti" créés par la question X . |
Les Limites de ce modèle sont que InfoX(T) tend vers 0 lorsque les tests ont beaucoup de choix de réponses. Ceci a pour conséquence que le GainX(T) tendra vers le gain maximum. Afin de remédier à cette lacune, Quinlam propose le GainRatio(X). Ceci consiste à diviser le gain par un facteur relié au nombre de choix de réponses. Ce facteur se nomme SplitInfo(X).
| NOM | EQUATION |
| GainRatioX(T) | (Info(T) - InfoX(T))/SplitInfo(X) |
| SplitInfo(X) | S nb(Ti)/nb(T) * Log2 (nb(Ti)/nb(T)) Pour tous les sous ensembles "Ti" créés par la question X . |
Afin de bien comprendre la Problématique de la quantification de l'information d'une série d'enregistrements, voici un graphique représentant l'information(Y) qui sera attribuée à un ensemble de données pour toutes les proportions en enregistrement de la classe désirée(X) tel que proposé par Quinlam.
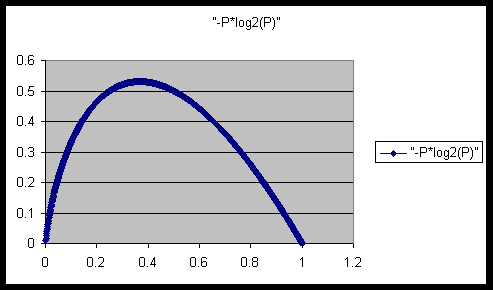
L'information que nous tentons de quantifier doit nous permettre de limiter la fragmentation des enregistrements appartenant à la même classe. Afin de représenter l'information d'un ensemble d'enregistrements, Quinlam propose de faire la somme pondérée du nombre de bits nécessaire pour représenter la probabilité de chaque classe. Donc 2 exp (-nb de bits) = Probabilité implique que Log2( probabilité )= nb de bits. La pondération du nombre de bits n'est que la probabilité de chaque classe. Donc l'information sur une classe est sa probabilité fois le nombre de bits pour la représenter. Afin de limiter la fragmentation, le modèle utilisé par Quinlam permet :
Il existe d'autres équations pouvant être utilisées pour calculer l'information. Voici une référence sur une autre méthode pour calculer l'information, voir référence[11].
L'algorithme qui nous permet de construire l'arbre de décisions selon la notion de gain tel qu'expliqué ci-haut est basé sur l'appel récursif à la fonction Tree(...).Voici une description approfondie de l'algorithme utilisé :
Pour mieux comprendre la construction d'un arbre, nous allons expliquer le fonctionnement de la première fragmentation dans la création d'un arbre. Afin de trouver la question qui nous permet de choisir la question qui fragmentera notre arbre, nous devons choisir celle qui minimise la perte d'information de l'échantillon (GainX). Pour trouver cette question, nous devons trouver l'information associée à l'échantillon que nous voulons subdiviser. L'information (info(T)) ainsi trouvée sera le référentiel pour trouver la gain minimum.
Voici l'équation du gain : GainX(T) = Info(T) - InfoX(T)
Par la suite, nous calculons l'information de l'échantillon fragmenté par chaque questions (InfoX(T)). À cette étape, il nous est possible de trouver la question à poser en choisissant celle qui à un Gain le plus faible. S'il reste des questions à poser, nous appellerons la fonction Tree pour tous les sous échantillons créés par cette question. Comme vous pouvez le remarquer, cette fonction sera appelée récursivement sous certaines conditions.
Description:Fonction récursive, qui fragmente l'échantillon d'après la meilleure question (fonction du gain maximum). Cette fonction est rappelée pour chaque fragment de l'échantillon.
Paramètre: Échantillon : l'ensemble des enregistrements que nous désirons fragmenter.
Retour: La racine de l'arbre
(
Calcul de Info(Échantillon)
Pour toutes les questions "Xi" pouvant encore être posées
Calculer InfoX( Xi, Échantillon)
Calculer le Gain(Xi, Échantillon)
Si il reste des attributs sur lesquels on peut poser des questions
alors Choix de la Question "Xi" ayant le plus grand Gain
Séparation de l'échantillon en N sous échantillons selon la question choisie
Pour les N sous échantillons
Si les enregistrements en faisant partie n'appartiennent pas tous à la même classe et qu'il reste des questions à poser
Alors appeler Tree( ième sous échantillon)
)
Afin de contrôler la capacité lors de la construction, deux approches sont possibles. La première consiste à contrôler la construction de l'arbre en mettant des restrictions sur le nombre minimum d'enregistrements par noeud. La deuxième consiste à imposer un seuil sur le gain pour faire l'explosion d'un noeud. Ces deux méthodes sont appliquées directement durant la construction et impliquent l'ajout de deux conditions dans l'algorithme de la création de l'arbre.
La ligne « Choix de la Question "Xi" ayant le plus grand Gain » de l'algorithme sera remplacé par
« si il y a plus de N enregistrements à ce niveau et que le gain maximum est supérieur à MinGain
alors Choix de la Question "Xi" ayant le plus grand Gain
sinon ne rien faire »
Nous parlons d'élagage de l'arbre lorsque nous cherchons à éliminer les explosions des noeuds qui n'entraînent aucune amélioration sur l'erreur générale de l'arbre. Quinlam nous propose dans son livre de faire l'élagage à partir des données d'entraînement en considérant une probabilité d'erreur sur chacune des valeurs des enregistrements. Nous n'avons pas retenu cette méthode car nous préférions faire l'élagage à partir d'échantillons n'ayant pas servi à la construction de l'arbre. Tout d'abord il nous est nécessaire de définir comment nous procédons pour calculer l'erreur d'un arbre sur ses données d'entraînement. Ce pourcentage nous donne un indice sur la prédiction maximale que l'arbre pourra atteindre. Voici la manière utilisée pour calculer l'erreur d'un noeud:
| NOM | EQUATION |
| Erreur(arbre) | S Erreur_Pond(j) :Somme de l'erreur
pondérée de chaque branche du premier niveau de
l'arbre. La pondération est le rapport entre le nombre
d'enregistrements la branche sur le nombre
d'enregistrements de la branche supérieur. Si la branche contient d'autres branches, la fonction sera appelée récursivement jusqu'à ce que l'on aboutisse à des feuilles(Condition d'arrêt). |
La méthode implantée consiste à éliminer les noeuds apportant peu d'information. Afin de réaliser cet élagage, nous calculons l'erreur de l'arbre plus une constante fois le nombre de feuilles avant puis après le retrait d'un noeud. Nous appellerons ce calcul l'erreur d'élagage. Nous retirons le noeud apportant la plus grande amélioration positive de l'erreur d'élagage. Nous ré-exécutons ces étapes tant qu'une amélioration positive de l'erreur d'élagage est encore possible.
| NOM | EQUATION |
| ErreurElagage(branche) | S Erreur_Pond(j) + A * nombre de
feuilles A: alpha, paramètre de contrôle de la capacité. |
Nous nous sommes inspirés de la section sur les arbres de décisions de Cart du cours Algorithmes d'apprentissages[12]. Cette algorithme permet le contrôle de la capacité en limitant la spécialisation de l'arbre sur les données d'entraînement. Voici une description approfondie de l'algorithme utilisé :
Afin de contrôler la capacité, nous utilisons une technique qui consiste à trouver les branches qui n'influencent pas significativement la généralisation. Pour se faire, nous calculons l'erreur de classification de l'arbre plus un facteur (alpha) fois le nombre de feuilles lorsque la branche est considérée comme une branche et lorsqu'elle est considérée comme une feuille. Alpha est le paramètre pour contrôler la capacité. Nous comparons ces deux résultats pour toutes les branches de l'arbres et nous éliminons celle ayant la plus grande variation positive. La branche à éliminer sera remplacée par une feuille associée à la classe la plus probable. Cette étape sera faite tant qu'il y aura des branches dont le calcul entraînera des variations positives.
Voici la fonction d'élagage sous forme d'algorithme :
Paramètre: branche: Arbre que nous voulons simplifier.
Retourne: La racine de l'arbre simplifiée
(
Faire
Recherche de toutes les banches de l'arbres
Pour Toutes les branches
Calculer l'erreur d'élagage lorsque la branche est considérée comme un branche puis comme une feuille.
Si l'on retrouve au moins une variation positive de l'erreur d'élagage pour une des branches
Alors Remplacer la branche ayant la plus grande variation par la feuille la plus probable
Sinon Sortir de la boucle
)
TRAITEMENT DES ATTRIBUTS CONTINUES
Il est maintenant venu le temps d'éclaircir la manière dont nous allons procéder lorsque nous traiterons des attributs de type continu. Afin de déterminer le seuil qui engendrera le gain maximum, nous calculons le gain pour toutes valeurs comprises entre deux valeurs consécutives.
Description:
Fonction permettant de trouver le meilleur seuil en fonction du gain.
Paramètre: NoAttributContinu : numéro de l'attribut de type continu dont nous voulons avoir le meilleur seuil.
Retourne: Le seuil optimal.
(
Évaluer le gain en utilisant comme seuil tous les points se situant entre 2 valeurs successives possibles
Conserver le seuil du gain maximum et le retourner.
)
Lors de l'implantation, nous avons optimisé cette fonction en mettant à jour la distribution des classes pour chaque seuil. Cette méthode nous permet de tester tous les seuils pour un coût en temps de calcul assez faible. Supposons que nous ayons N attributs et M seuils, sa complexite passe de O(N*M) à O(N).
L'algorithme présenté assume que nous connaissons toutes les valeurs des attributs pour chacun des enregistrements. Sachant que chaque test au niveau des branches est basé sur un seul attribut, il devient problématique de traiter les enregistrements ayant des attributs manquants.
Sachant que les données de la vie courante sont souvent incomplètes, il nous est indispensable de trouver un moyen de remédier à ce problème.
Deux choix s'offrent à nous :
La modification du critère de gain lors de la construction consiste à introduire un facteur proportionnel au nombre d'attributs connus : GainX(T) = K * (Info(T) - InfoX(T))
De la même facon, la définition de SplitInfo(T) peut-être modifié.
Supposons que la valeur de l'attribut impliqué dans l'un des tests est manquante. Le résultat ne peut être déterminé. La solution proposée est d'explorer tous les résultats possibles et de les combiner arithmétiquement. Plus précisément, il existe plusieurs chemins à parcourir à partir du noeud associé à la question sur un attribut manquant. Le résultat est une distribution des classes à la place d'une classe unique. Finalement, la classe la plus probable est prise comme décision.
VÉRIFICATION DE L'IMPLANTATION
Afin de vérifier notre implantation, les résultats ont été comparés à ceux obtenus à partir de C4.5. Les données ayant permis de faire ces comparaisons sont :
Données pour la prédiction de jouer au golf : 15 enregistrements, 2 classes (asgolf.specs, golf.specs,golf.data)
Les fichiers ayant l'extension "c45" représentent les arbres de décisions générés par C4.5. Ceux ayant l'extension "ad" représentent les arbres de décisions générés par la libraire AD. La représentation des arbres au moyen d'AD considère les numéros d'attributs pour les tests, tandis que dans celle de C4.5 considère les noms associés aux attributs.
| Résultats | |
| C4.5 | golf.c45 |
| AD | golf.ad |
Données iris: 150 enregistrements, 6 classes (axvi.specs,si.specs, iris.specs,iris.data)
| Résultats | |
| C4.5 | iris.c45 |
| AD | iris1.ad |
PS: Toutes les expérimentations ci-haut n'ont utilisé aucun contrôle de capacité.
Le contrôle de la capacité est tel un arbre élagué. Voici un fichier de résultats présentant l'amélioration de l'erreur de généralisation dans le cas "iris" tel que vu précédement: test_arbre
Le fichier subséquent nous permet de voir sur un exemple simple d'arbre avant et après un élaguage: elaguage_iris.ad
Ayant vérifié la validité des résultats de notre implantation, il est venu le temps de présenter plusieurs expérimentations que nous avons faites au moyen des abres de décisions. Afin de respecter la théorie de l'apprentissage, nous avons utilisé une facilité de la librairie AD pour séparer l'ensemble de données en deux groupes: un pour l'apprentissage et l'autre pour nous donner un estimé de l'erreur de généralisation. Cette facilité sera utilisé dans toutes les expérences subséquentes. AD nous permet aussi faire des expériences en séparant l'ensemble d'apprentissage en N ensemble afin de créer N arbres distincts.Cette facilité est caractérisée par l'utilisation d'un XvTester. AD nous permet aussi de créer en utilisant à chaque itération une partie plus grande des données d'apprentissage. Cette facilité est caractérisée par l'utilisation d'un Scanner. Afin de trouver le meilleur alpha servant au contôle de la capacité, il est possible d'utiliser une facilité de la librairie AD caratérisé par l'utilisation d'un Experiment.
Letter-recognition : 20 000 enregistrements, 26 classes(asletter.specs , axvld.specs , letter-recognition.data)
| Résultats (Scanner) | |
| Arbre | arbre: letter.ad |
| Mesures | mesures-letter.ad |
Données iris: 150 enregistrements, 6 classes (axvi.specs , iris.specs , iris.data)
| Résultats (XVtester) | |
| Arbre | iris2.ad |
| Mesures | mesures-iris2.ad |
LES STRUCTURES DE DONNÉES ET LES INTERFACES
Arbre (DecisionTree.h)
Noeuds (DecisionTreeNode.h)
Utlitaires (decision_tree_util.h)
Mesureur (DecisionTreeMeasurer.h)
Spécifications pour l'utilisation des arbres de décisions dans AD (DecisionTree.ss)
Arbre (DecisionTree.cpp)
Noeuds (DecisionTreeNode.cpp)
Utlitaires (decision_tree_util.cpp)
Mesureur (DecisionTreeMeasurer.cpp)
L'objectif de ce projet était d'ajouter la possibilité de faire de la prédiction au moyen d'arbres de décisions à la libriairie AD. Dans l'implantation réalisée, seule la classification est traitée. Nos résultats concordent avec ceux de C4.5, nous considérons donc que la réalisation du projet est un succès. N'ayant pu tester suffisamment l'implantation, le module d'arbre de décisions est une version alpha. Les attributs non-connus n'ont pas été traités, ils sont tous considérés connus. Ceci est une amélioration qui pourrait être faite dans les versions ultérieures. Breiman nous propose un modèle d'arbre de décisions appelé « perceptrons decisions tree». Chaque noeud de l'arbre est un perceptron qui permet de faire des tests sur plusieurs attributs à la fois. Ce modèle pourrait être une améliration intéressante à étudier et à implanter. En ce qui concerne des améliorations en terme de performance sur les attributs de type continu, J. Ross Quinlam nous propose une alternative,voir la référence[13]. Sachant que le contrôle de la capacité est biaisé car nous utilisons les données d'entrainements pour élager notre arbres, il serait important de pouvoir faire l'élagage sur un ensemble de donnée distinct dans une future version. La partie régression fut réalisée à la suite de mon stage par Ayman Farhat, Microcell-labs. Deux compagnies de finance ont acheté le produit.
[1]Microcell-Labs : http://www.microcell.ca/en/labs/labs.htm
[2] Quinlam, J. Ross. C4.5 : Programs for machine learning. Morgans Kaufmann publishers, 1993 http://www.mkp.com/books_catalog/1-55860-240-2.asp
Des améliorations ont été apportées au programme C4.5. Pour plus d'informations veuillez consulter la référence [14].
Référence sur l'auteur: Quinlam, J. Ross : http://www.cse.unsw.edu.au/~quinlan/
[3] Database ftp://ftp.ics.uci.edu/pub/machine-learning-databases/
[4] Microcell - Compagnie en télécommunication: http://www.microcell.ca
[5]Building Classification Models: ID3 and C4.5 http://yoda.cis.temple.edu:8080/UGAIWWW/lectures/C45/
[6]Breiman L., Friedman J. H., Olshen R. A., Stone C. J. Classification and regression trees. Chapman & Hall, 1984
[7] C4.5 Release 8 : http://www.cse.unsw.edu.au/~quinlan/patch-R8.tar.Z
[8] Bengio Yoshua, Theorie de l'apprentissage, http://www.iro.umontreal.ca/~bengioy/ift6264
[9] Notes de cours, APPRENTISSAGE A PARTIR D'EXEMPLES , François Denis Rémi Gilleron , Université Charles de Gaulle http://l3ux02.univ-lille3.fr/~gilleron/PolyApp/cours.htm
[10] Hyafil L. and Rivest R.L. Constructing optimal binary decision trees in NP-Complete. Information processing letters 5,1,15-17,19766
[11] IEEE Transactions on pattern analysis and machine intelligence, Vol 19, N0. 12, December 1997
[12] (IFT6265) ALGORITHMES D'APPRENTISSAGES http://www.iro.umontreal.ca/~bengioy/ift6265
[13] "Improved use of continuous attributes in C4.5" author : J. Ross Quinlan Journal:JAIR : http://www.cs.washington.edu/research/jair/contents/v4.html
[14] New devellopement on decision tree by J. Ross Quinlam : http://www.rulequest.com/index.html