Algoritmo de Compresiµn de HuffmanEl algoritmo de compresiµn de Huffman se basa en asignar una longitud variable a cada carÃcter en funciµn de la frecuencia en que aparece en el archivo. Cuanto mas aparezca un carÃcter menor serà su tamaþo. Pasos del algoritmo:
Por ejemplo para el texto: ABRACADABRAPATADECABRA
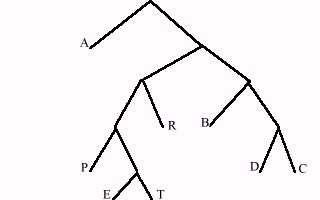
(E, 1) (T, 1) (P,1) (D, 2) (R,3) (B,3) (A,9) Y el Ãrbol resultante:
HaciÕndolo asÚ, los cµdigos de los caracteres serian:
Para descomprimir un archivo asÚ comprimido se tiene una tabla con la codificaciµn de los caracteres. Se va leyendo bit a bit hasta que localicemos una subcadena que se encuentre en la tabla, la sustituimos por su carÃcter y seguimos leyendo el siguiente bit. Este algoritmo funciona ya que para un carÃcter solo hay un recorrido posible en el Ãrbol y dado un recorrido solo hay un carÃcter posible que lo cumpla. Luis Jose Cabellos |