Redes, endereþos, nomes e serviþos - introduþãoProfessor Adjunto do Departamento de Engenharia Informßtica do ISEP IntroduþãoA utilizaþão de redes de computadores faz hoje parte da cultura geral. A explosão da utilizaþão da "internet" tem aqui um papel fundamental, actualmente quando se fala de computadores estß implicito que os mesmos estão ligados a uma rede. Muitos utilizadores consideram completamente inutil um computador sem ligaþão Ó "internet". Embora as aplicaþões sejam cada vez mais voltadas para os utilizadores e dispensem cada vez mais o conhecimento sobre os principios de funcionamento, a existencia destes conhecimentos tem um papel fundamental numa utilizaþão segura e eficaz das redes.  O que se designa por "internet" Ú na realidade um conjunto de redes e computadores que se encontram interligados a nÝvel mundial, os meios usados para garantir esta interligaþão são muito diversos, recorrendo Ós redes p·blicas de comunicaþões, baseadas em cabos electricos ou ¾pticos, terrestres ou submarinos e ligaþões via rßdio terrestres ou via-satÚlite. Com tecnologias de transmissão tão diversas Ú necessßrio um elo comum que permita a transferência de dados entre qualquer equipamento ligado Ó "internet", esse elo Ú o protocolo de rede, no caso da "internet" designado por "Internet Protocol" e abreviado para IP. Uma das missões importantes de um protocolo de rede Ú portanto assegurar a transferêmcia de dados entre redes que usam tecnologias de transmissão diferentes. EndereþamentoUma das primeiras preocupaþões quando pensamos numa rede Ú a forma de identificar cada uma das mßquinas que estão ligadas. ╔ um problema identico ao que acontece quando pretendemos enviar uma carta a alguÚm ou telefonar a alguÚm, necessitamos, respectivamente, do endereþo do destinatßrio ou do n·mero do telefone. Desde logo uma caracteristica fundamental de um endereþo Ú ser ·nico, isso pode ser um grande problema numa rede global como a "internet", não podemos usar simplesmente o endereþo que nos apetecer. O formato dos endereþos de rede depende do protocolo de rede, actualmente o mais divulgado Ú o IP versão 4, este protocolo utiliza apenas 4 octetos (conjuntos de 8 bits que permitem representar n·meros de 0 a 255) para identificar cada destino. Este n·mero de octetos Ú muito reduzido para a expansão actual da "internet", não existem endereþos suficientes para a quantidade de mßquinas que lhe estão ligadas. O problema Ú ainda agravado pela necessidade de delegar em entidades nacionais a atribuiþão de novos endereþos o que implica reservar uma determinada quantidade para cada uma dessas entidades. Esta Ú uma das razões pela qual foi desenvolvido o IP versão 6, entretanto foram encontradas outras soluþões para a escasses de endereþos e o IPv6 não Ú ainda muito usado. Na tabela seguinte apresentam-se alguns endereþos para outros tantos protocolos de rede:
Seja qual for o protocolo de rede, tal como acontece quando se envia uma carta a alguÚm, os dados transferidos pela rede devem conter dois endereþos: origem e destino. Isto Ú fundamental por duas razões:
A maioria dos esquemas de endereþamento suportam dois tipos de endereþos de destino:
Os endereþos "multicast" tÛm diversas utilidades pois permitem difundir informaþÒo para vßrios n¾s de uma forma expedita e rßpida. Um endereþo "multicast" muito comum Ú o endereþo de "broadcast" que corresponde a todos os n¾s existentes numa dada rede. Algumas redes suportam ainda endereþos "ANYCAST" que, tal como os endereþos "MULTICAST" identificam vßrios n¾s, contudo apenas obrigam a rede a entregar os dados a um dos n¾s do conjunto. Modelo cliente-servidorEste Ú o modelo que serve de referência Ó maioria das comunicaþões em rede, baseia-se no conceito de prestaþão de um serviþo e define um dißlogo tÝpico de pedido-resposta:
Deste modelo podemos tirar algumas conclusões imediatas:
O principal problema que se levanta Ú a necessidade de os clientes conhecerem previamente o endereþo do servidor. A questão Ú que as aplicaþões clientes são manuseadas directamente pelos utilizadores que teriam de fornecer o endereþo do servidor. Nomes de mßquinasPara um humano os endereþos de rede não têm qualquer significado e não se pode exigir a um utilizador que os tenha sempre presentes. Se isso jß Ú impraticßvel para o IPv4, imagine-se para o IPv6. Devido Ó dificuldade de os utilizadores lidarem com endereþos de rede, foi desenvolvida uma alternativa que Ú o nome de mßquina. Consiste em "baptizar" as mßquinas dando-lhes nomes mais ou menos fßceis de fixar, depois Ú necessßrio um mecanismo que efectue a traduþão automßtica. Estes nomes de mßquinas equivalem por isso a endereþos e como tal tÛm de manter a caracteristica de serem ·nicos. Os clientes (aplicaþ§es) recebem do utilizador o nome da mßquina onde estß o servidor e utilizam o referido "mecanismo automßtico" para obter o respectivo endereþo de rede. Esta operaþão de obtenþão do endereþo de rede apartir do nome da mßquina designa-se por "resoluþão do nome". DNS - "Domain Name System"Se numa rede local, com algumas dezenas de mßquinas a implementaþão de um mecanismo de resoluþão de nomes Ú simples e pode ter vßrias abordagens, na "internet" torna-se muito complicada devido Ó quantidade de mßquinas envolvidas. Se existisse uma base de dados contendo um registo para cada mßquina ligada Ó "internet" ela seria enorme e a pesquisa sobre ela muito morosa. A soluþão adoptada consiste na distribuiþãao desta base de dados segundo nomes que se designa por domÝnios, para facilitar ainda mais a resoluþão, os domÝnios estão organizados em forma hierßrquica, esta base de dados e respectivos serviþos têm a designaþão "Domain Name System" (DNS). 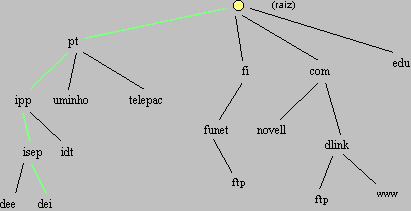 Por uma questão de tolerância a falhas, cada domÝnio tem pelo menos dois servidores de nomes onde reside a base de dados que contÚm os mapeamentos "nome<->IP" para todas as mßquinas desse domÝnio. Como foi referido os domÝnios estão organizados em forma hierßrquica, assim cada domÝnio pode conter vßrios subdomÝnios com os seus respectivos servidores de nomes, cada domÝnio tem tambÚm de conhecer os endereþos dos servidores de nomes dos subdomÝnios que contem. A resoluþão dos nomes Ú realizada de forma descendente desde os chamados domÝnios de topo, todos os servidores de nomes têm de conhecer os endereþos dos servidores de nomes dos domÝnios de topo. Os domÝnios de topo são:
Tantos os servidores de nomes como os clientes guardam durante algum tempo, em "cache" local, as resoluþões que vão realizando, isto aumenta bastante a eficiência do sistema. Quando um servidor de nomes recebe um nome de mßquina para resolver podem verificar-se vßrias situaþões:
Para identificar inequivocamente uma mßquina, ao nome da mßquina devem ser concatenados os sucessivos domÝnios, separados por um ponto, atÚ chegar ao domÝnio de topo. Por exemplo o nome "alvega" identifica a mßquina com nome "alvega" no domÝnio local, o nome "alvega.dei.isep.ipp.pt" identifica a mßquina com nome "alvega" que se encontra no domÝnio "dei", do domÝnio "isep", do domÝnio "ipp", do domÝnio de topo "pt". Os nomes de mßquinas simples, sem a sucessão de domÝnios atÚ ao topo, dizem-se "não qualificados" e têm um significado que depende do local onde nos encontramos, um nome de mßquina com a sucessão de domÝnios atÚ ao topo diz-se "qualificado" e tem o mesmo significado em qualquer ponto da "internet". O serviþo de nomes DNS não se limita a resolver nomes de mßquinas, dando outras indicaþões, por exemplo como enviar correio-electr¾nico para esse domÝnio (identificaþÒo das mßquinas que recebem correio-electr¾nico). Outra caracteristica importante do DNS Ú a possibilidade de definir nomes alternativos, conhecidos habitualmente por "aliases". Nas bases de dados DNS, cada mßquina, alÚm do nome "normal", pode ter um ou mais nomes alternativos, os nomes alternativos são tratados exactamente da mesma forma, tanto o nome normal como os alternativos, quando resolvidos produzem o endereþo de rede da mßquina. Os nomes alternativos são muito ·teis porque existem certos nomes de mßquina que representam serviþos disponibilizados. Por exemplo "www" para servidores "web", "ftp", "mail", etc. Recorrendo a nomes alternativos Ú possÝvel instalar vßrios serviþos na mesma mßquina e usar estes nomes representativos que acabam por apontar todos para o mesmo endereþo de rede. Os nomes alternativos são tambÚm bastante ·teis para os administradores pois quando querem transferir um serviþo de uma mßquina para outra basta mudar o "alias" e não Ú necessßrio alterar os nomes das mßquinas que Ú bastante mais complicado. Na realidade uma dada mßquina pode nem sequer ter conhecimento que tem determinados nomes alternativos, todo se passa a nÝvel dos servidores DNS. ResoluþÒo de nomes NetBIOS - WINSA especificaþÒo NetBIOS, usada em redes locais, possui os seus pr¾prios mecanismos de resoluþÒo de nomes. Ao contrßrio do sistema DNS, o sistema de nomes NetBIOS Ú totalmente dinÔmico, os n¾s podem usar o nome que bem entenderem, contudo esse nome tem de ser aceite pela rede ("name registration"). O registo de um nome na rede envolve o envio de um pedido em "broadcast" contendo o nome a registar, se jß existe na rede um n¾ com o mesmo nome, este "protesta" e o registo nÒo Ú aceite. A resoluþÒo de nomes NetBIOS consiste no envio de um pedido com o nome a resolver ("name query") em "broadcast" para a rede. A n¾ que possui esse nome responde, ficando-se a conhecer o endereþo a que corresponde o nome. Este mecanismo de resoluþÒo de nomes tem a grande vantagem de dispensar qualquer tipo de administraþÒo ou configuraþÒo prÚvia, mas apresenta algumas desvantagens:
Para resolver estes problemas a Microsoft desenvolveu o serviþo WINS ("Windows Internet Name Service"), baseado nos RFC1001 e RFC1002. O principio Ú simples: substituir o papel dos "broadcast" para a rede por envios "unicast" para um n¾ especial onde funciona o servidor WINS. O servidor WINS mantÚm uma base de dados com os n¾s activos, os n¾s registam-se usando o pedido "name registration", o servidor consulta a sua base de dados para saber se o nome estß disponÝvel, em caso afirmativo aceita o pedido e adiciona o novo nome Ó base de dados. Periodicamente os n¾s enviam pedidos "name refresh", caso contrßrio sÒo eliminados da base de dados. Alguns servidores WINS permitem a existÛncia de nomes permanetes cujo registo apenas Ú aceite para endereþos IP preestabelecidos, desta forma podem evitar-se conflitos com nomes de servidores crÝticos. A resoluþÒo de um nome consiste agora no envio de um pedido "name query" para o servidor WINS que para responder usa a sua base de dados. A utilizaþÒo de um servidor WINS resolve os problemas apontados, deixa de ser usado o "broadcast" e por isso a resoluþÒo de nomes funciona mesmo quando os n¾s se encontram em redes diferentes. Para que a resoluþÒo WINS funcione Ú contudo necessßrio manter uma condiþÒo: todos os n¾s tÛm de usar o mesmo servidor WINS. Os servidores WINS da Microsoft suportam ainda mecanismos de replicaþÒo que, para efeitos de redundÔncia, permitem manter vßrios servidores desse tipo perfeitamente sincronizados. De referir ainda que, mesmo usando o serviþo WINS, os n¾s NetBIOS continuam a usar "broadcast" para a eventualidade de existirem na rede n¾s que nÒo usam o mesmo servidor WINS. Os n¾s NetBIOS registam sempre o seu nome em todas as redes a que estÒo ligados ("broadcast") e em todos os servidores WINS que conhecem. O tipo de n¾ NetBIOS ("NetBIOS node type") define o comportamento na resoluþÒo de nomes:
Actualmente o tipo de n¾ mais usado Ú H-Node, deste modo apenas Ú usado "broadcast" se a resoluþÒo pelos servidores WINS falha. A forma de configurar o tipo de n¾ varia muito com a versÒo do sistema operativo, alguns sistemas operativos permitem ainda usar a resoluþÒo DNS para nomes NetBIOS, ou mesmo servidores DHCP. ServiþosComo foi jß indirectamente referido, cada mßquina, pode ter em funcionamento simultaneo vßrios servidores de diferentes de tipos. Por outro lado cada mßquina pode ter m·ltiplos clientes em funcionamento. Uma vez que a ligaþão Ó rede Ú geralmente ·nica, hß necessidade de definir um mecanismo l¾gico que permita separar e evitar interferências entre as diferentes comunicaþões em curso atravÚs da ligaþão fÝsica. Este tipo de operaþão Ú vulgarmente designado por multiplexagem. A soluþão adoptada consiste na atribuÝþão de um n·mero de identificaþão (tipicamente um n·mero inteiro positivo de 16 bits), assim os dados que chegam a uma mßquina têm associados a sÝ um identificador numÚrico, jß no interior da mßquina, este identificador Ú usado para fazer chegar os dados Ó aplicaþão correcta, por exemplo um servidor. Este processo Ú usado em diversos nÝveis, permite por exemplo que uma mßquina use vßrios protocolos de rede. Nos protocolos de rede estes identificadores são conhecidos por "portos" ("ports"). Esta designaþão tem haver com comparar a mßquina com um paÝs, sendo por isso os portos locais de chegada possÝveis. Em portugues, alÚm da designaþão "porto" pode usar-se a designaþão "porta". Qualquer aplicaþão que utiliza e rede, seja um cliente ou um servidor, tem de usar uma porta, dado o seu posicionamento, uma aplicaþão servidora tem de usar um n·mero de porta "bem definido". Esta necessidade deriva do facto de o primeiro contacto num dißlogo segundo o modelo cliente-servidor ser do cliente para o servidor. Para efectuar este contacto o cliente necessita não apenas do endereþo da mßquina onde o servidor se encontra, mas tambÚm do n·mero de porto onde o servidor escuta os dados. Para cada tipo de servidor/serviþo estß estabelecido um n·mero de porto fixo, tanto o servidor como o cliente sabem qual Ú esse n·mero. O servidor porque Ú nesse porto que tem de receber o pedido e o cliente porque Ú para esse porto que tem de enviar o pedido. Os utilizadores não necessitam de conhecer estes n·meros de porto, eles estão implicitos pela aplicaþão cliente que Ú usada. Alguns n·meros de porto frequentemente utilizados no primeiro contacto cliente-servidor são:
Por exemplo um servidor TELNET escuta os pedidos dos clientes no porto 23. Por seu lado os clientes TELNET enviam os pedidos para o porto 23 da mßquina que o utilizador pretende. Deste modo quando se usa um cliente TELNET apenas temos de indicar o nome do servidor, o n·mero de porto estß implicito. Caso o utilizador o pretenda, a maioria dos clientes TELNET permite que se utilize outros portos para alÚm do 23. O referido nÒo implica que um servidor TELNET tenha obrigatoriamente de usar o porto 23, simplesmente se usar outro porto, a menos que os utilizadores tenham conhecimento de qual o n·mero do porto usado, nunca vÒo conseguir contactar esse servidor. URL ("Uniform Resource Locator")Os URL sÒo um subconjunto dos URI ("Uniform Resource Identifier"), um URL Ú um "string" formatado que permite identificar o acesso a um dado recurso. A definiþÒo de URI Ú mais lata jß que trata apenas da identificaþÒo de um recurso. Os URL tÛm a seguinte forma:
O termo "acesso relativo" insere-se no contexto do hipertexto (ex.:html), no qual os recursos (documentos) contÛm ligaþ§es a outros recursos, num documento deste tipo um URL relativo tÛm como ponto de partida a localizaþÒo do documento corrente. Dependendo dos mÚtodos de acesso, cada um dos componentes pode suportar vßrias extens§es, por exemplo "//NOME-DO-SERVIDOR" pode ter a seguinte forma:
O componente "/CAMINHO" pode ter formatos muito diversos, para o acesso a ficheiros (file:, ftp:, http:, ...) identifica uma sequÛncia de direct¾rios e nome do ficheiro. Se for identificado um direct¾rio em lugar de um ficheiro serß fornecida uma listagem do conte·do do direct¾rio (para acesso "http:" os servidores podem devolver o ficheiro "index.html" ou "index.htm"). UNC ("Universal Naming Convention")O UNC Ú uma notaþÒo muito usada pela Microsoft, no contexto das rede NetBIOS, para identificar recursos na rede (note-se que as barras sÒo descendentes, estilo MS-DOS):
Pilhas de protocolos - TCP/IPEm ambiente Unix o ficheiro "/etc/services" contÚm informaþão sobre os n·meros de porto e serviþos estabelecidos para cada um deles: # # Note that it is presently the policy of IANA to assign a single well-known # port number for both TCP and UDP; hence, most entries here have two entries # even if the protocol doesn't support UDP operations. # Updated from RFC 1340, ``Assigned Numbers'' (July 1992). Not all ports # are included, only the more common ones. # # from: @(#)services 5.8 (Berkeley) 5/9/91 # $Id: services,v 1.9 1993/11/08 19:49:15 cgd Exp $ # tcpmux 1/tcp echo 7/tcp echo 7/udp discard 9/tcp discard 9/udp systat 11/tcp daytime 13/tcp daytime 13/udp netstat 15/tcp qotd 17/tcp msp 18/tcp msp 18/udp chargen 19/tcp ftp-data 20/tcp ftp 21/tcp fsp 21/udp ssh 22/tcp ssh 22/udp telnet 23/tcp Pode observar-se no extracto que cada linha inicia-se com um nome de serviþo, segue-se um n·mero de porto e respectivo protocolo, no caso "udp" ou "tcp". A realidade Ú que o protocolo IP não define n·meros de porta, estes são definidos pelos protocolos "udp" e "tcp" que são usados pelas aplicaþões, por exemplo clientes e servidores, este conjunto de protocolos Ú conhecido por TCP/IP. A figura seguinte ilustra um conjunto de protocolos (incluindo a pilha TCP/IP) a funcionar no interior de uma mßquina ligada a uma rede local tipo "ethernet". 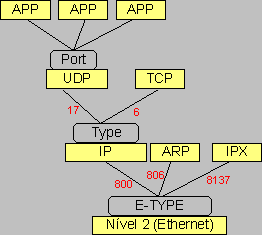 Podem observar-se vßrios pontos de multiplexagem que culminam, no caso "internet" com a definiþão de n·meros de porta, quer para o protocolo "udp", quer para o protocolo "tcp". Cada nÝvel usa um formato especifico (PDU - "Protocol Data Unit") que contÚm os dados a transportar e informaþÒo de controlo especÝfica desse protocolo. Durante a emissÒo de dados (sentido descendente na pilha de protocolos), cada camada "passa" Ó camada inferior os seus PDU. Na camada inferior, o PDU recebido da camada superior Ú interpretado como dados abstractos aos quais vai ser adicionada nova informaþÒo de controlo. Este mecanismo Ú normalmente conhecido por encapsulamento e pode ser observado na figura seguinte:
O protocolo "tcp" ("Transmission Control Protocol") Ú orientado Ó conexão, sendo adequado para serviþos em que a fiabilidade Ú importante e serviþos que implica a existÛncia de um dißlogo prolongado entre cliente e servidor (sessão). O protocolo "udp" ("User Datagram Protocol") não Ú orientado Ó conexão, os dados são enviados em blocos independentes entre sÝ. ╔ adequado para serviþos cuja fiabilidade não Ú muito importante e em que o dißlogo cliente-servidor se resume ao envio de um ·nico pedido e devoluþão de uma ·nica resposta.  AlÚm dos protocolos IP, UDP e TCP, a pilha TCP/IP contempla ainda alguns protocolos auxiliares, um deles Ú ICMP ("Internet Control Message Protocol"). Ao contrßrio dos anteriores o ICMP nÒo Ú usado para transportar dados das aplicaþ§es de rede, tal como o nome indica, trata-se do envio de mensagens de controlo. Algumas das principais mensagens ICMP sÒo:
Alguns documentos relacionados: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||