10. For BP1 old-timers...
Users of BP1 (the Apple IIc version)
will be happy to find all features of BP1 implemented in BP2 (version 2.4,
November 1993).
10.1 Tempo marking
The first rules of "-gr.dhin--", a grammar producing a North Indian
qa'ida (a set of variations used by tabla drum
players) look like:
S --> 4+4+4+4/6 S192
S192 --> etc.
...
The expression "4+4+4+4/6"
indicates how musical items derived from "S192" should be displayed.
In earlier versions of BP2 (before BP2.5.2) it was notated "4/4/4/4/6";
although this notation is still valid it should be abandoned for the sake of
clarity.
First consider "/6". This is
an
explicit tempo marker, indicating that each beat
of the metronome contains six sound-objects. (This is referred as
chegun
by Indian musicians.)
The sequence "4+4+4+4"
indicates how beats should be grouped in a measure (
tala) containing 16 beats (referred to as
tintal). Here the measure is divided into four
sections of four beats. Consequently, a musical item produced by this grammar
may for instance be displayed:
dhin--dhagena.dha--dhagena.dhatigegenaka.dheenedheenagena.¬
tagetirakita.dhin--dhagena.dhatigegenaka.teeneteenakena.¬
teeneteenakena.dheenedheenagena.dheenedha-dheene.dheenedheenagena.¬
tagetirakita.dhin--dhagena.dhatigegenaka.teeneteenakena.¬
tin--takena.ta--takena.tatikekenaka.teeneteenakena.¬
taketirakita.tin--takena.tatikekenaka.teeneteenakena.¬
teeneteenakena.dheenedheenagena.dheenedha-dheene.dheenedheenagena.¬
tagetirakita.dhin--dhagena.dhatigegenaka.dheenedheenagena
Beats are separated by
periods (that could be replaced with tabulations
in a word processor), and sections of the measure are displayed on different
lines. Here the item covers two measures, i.e. eight lines containing 32 beats
and 32x6 = 192 sound-objects (as expected).
Note that periods before line breaks '¬'
prevent the last beat from being merged with the first one of the next line.
If the
tala is
dhamar (14 beats divided 5+2+3+4) and tempo is
tigun, the header will be "5+2+3+4/3".
If periods are
inserted in data or grammar arguments, they are used by the compiler to change
the tempo. For example, if a,b,c are terminal symbols,
abba.bcca.bcca.abc.ccb
will be interpreted as
{1,abba}
{1,bcca}{1,bcca}{1,abc}{1,ccb}
and performed like:
/4 abbabccabcca /3 abcccb
The polymetric expression "{1,abba}" (meaning: "abba" is
performed during 1 beat) is more flexible than "/4 abba". The former
is a relative, and the latter an absolute, tempo specification.
Conversely, if a string of data is
selected and "
Show periods" is invoked (see the Control
panel, type cmd-=), beat and section markers are automatically inserted. For
instance,
3+4+2/4 abbabccabcca /3
abcccbaab /1 bbb
will be rewritten as:
abba.bcca.bcca.¬
abc.ccb.aab.b.¬
b.b
(See more examples in "-da.ShowPeriods".)
10.2 Parsing items
Parsing ("Analyze selection"
in the "Action" menu) is the attempt to check whether or not the
arbitrary item you selected might have been produced by the grammar. Parsing is
also called a
membership test. There are severe restrictions
in the grammar format that make this test valid. When compiling a grammar BP2
checks whether it is a "
true" BP grammar (see reference manual §7)
and then only it authorises parsing.
Grammar "-gr.dhin--" is an example of a "true" BP grammar.
First you should compile the grammar (cmd-k) and generate its
templates (see Control panel or "Action"
menu). Then produce a few items in the "Data" window. You will
notice that the produced items are displayed without any structural marker (brackets indicating repetitions, etc.). This display is
a comprehensive "score" for Indian drum players. Structural markers
will be automatically inserted when matching items against the templates.
Select one or several items and select "Analyse
selection" in the "Action" menu (or click the same on the Control
panel). BP2 will prompt you to use templates. Answer "yes". You may
then decide whether you want to find only the first template matching each item
and yielding a positive membership test, or check all
templates to find which ones are acceptable. While the first method yields a
quick assessment of the item in reference to the language generated by the
grammar, the second will also point out structural ambiguity, e.g. the same item
may be assessed "correct" by the grammar while matching several
templates:
>>> Analyzing item: /6
dhin--dhagenadha--dhagenadhatigegenakadheenedheenagenatagetirakitadhin--dhagenadhatigegenakateeneteenakenadhagenadhin--dhagenadha--dhagenadha--dhagenadha--tagetirakitadhin--dhagenadhatigegenakateeneteenakenatin--takenata--takenatatikekenakateeneteenakenataketirakitatin--takenatatikekenakateeneteenakenadhagenadhin--dhagenadha--dhagenadha--dhagenadha--tagetirakitadhin--dhagenadhatigegenakadheenedheenagena
Item matched template [15]
>>> Item matching
template [15] accepted by grammar...
Item matched template [19]
>>> Item matching
template [19] accepted by grammar...
Item matched template [20]
>>> Item matching
template [20] accepted by grammar...
10.3 Learning weights
The process of
weight inference has been introduced in (Kippen &
Bel 1992). Given a set of items accepted by the current grammar it is possible
to infer rule weights from the set of examples. The weight of each rule will be
the number of times it has been used in parsing the sample set. Weight
inference is used to improve the quality of randomly generated musical items by
increasing the probability that these items resemble a set of items given as an
input by an expert musician. See for instance the weights of rules in "-gr.dhin--".
Try this procedure as follows. Load "-gr.dhin--" and "-da.dhin--".
Compile the grammar and produce its templates. (It's a good idea to save the
current grammar with its templates, but remember that templates
should be computed again each time structural rules have been modified in the
grammar.) Now click "Save weights" on the Control panel to save
current grammar weights in a "-wg" file. Then click "Set weights"
and reset all weights to 0. Select all items in the "Data" window,
click "Learn weights" and answer default
options in all dialogs.
10.4 Keyboard encoding
It is possible to reprogram the keyboard
in order to type certain strings ("tokens") with a single key stroke.
This is generally used for the names of terminal sound-objects. Current
keyboard encoding is visible in window "Keyboard" and may be saved
with prefix "-kb". The name of the corresponding file (e.g., "-kb.kathak.azerty")
is automatically inserted on top of the alphabet file. Conversely, inserting a
name will prompt BP2 to load the declared "-kb." file as soon as the
alphabet file is loaded.
Using window "Keyboard" is
self-explanatory. To activate/deactivate encoding you may switch button "Use
these tokens" on and off, or check "Use tokens" / "Type text"
in the "Misc" menu, or type cmd-option t.
Only 52 characters may be mapped to
tokens. Any string shorter than 255 characters may be mapped to a key as a
token. Fig.30 shows the encoding used for Kathak material on an English
keyboard (QWERTY).
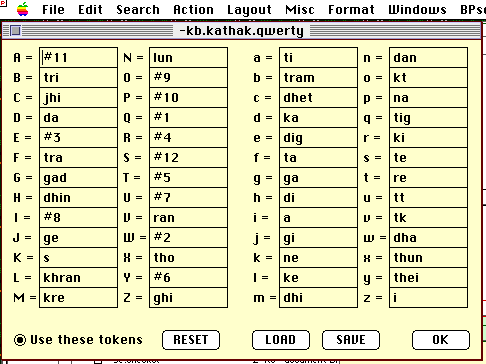 Fig.30 Keyboard encoding dialog
Fig.30 Keyboard encoding dialog
Keyboard encoding in versions e 2.5
takes different keyboard layouts into account. Two layouts are currently
supported: US (QWERTY) and French (AZERTY). The default layout is QWERTY, but
if you change it to AZERTY when tokens have been defined, then the mapping is
modified automatically so that tokens appear at the same locations on the
keyboard -- except for the ones mapped to the 'M' key, which cannot be remapped.
(When changing from AZERTY to QWERTY and vice-versa, the 'M' key is swapped
with another key that does not contain alphabetic characters.)
The AZERTY/QWERTY option is saved along
with the -kb.<filename> keyboard encoding.
10.5 Documentation of Indian music
An example of keyboard encoding is the
material contained "-da.kathak tihais". When
this data file is opened, it automatically calls the "-ho.kathak"
alphabet which in turn opens the "-kb.kathak.qwerty" encoding. (You
may change it to AZERTY if your keyboard is in French.) All tokens are
bols used by (Lucknow style) Kathak dancers in
North India, in a comprehensive transliteration designed by Andréine Bel.
Numbers used as terminal symbols (in the so-called "number
tihais
" are notated #1, #2, #3... (pronounce
ek, do, tin
... in Hindi, otherwise
one, two, three
...) because ordinary integers are reserved for indicating durations.
Indian rhythmic material lends itself to
descriptions by formal grammars, as exemplified by grammars "-gr.dhati", "-gr.dhin--", "-gr.dhadhatite" and their variants able to produce
qa'idas (theme and variations pieces) in the
Lucknow style of tabla drumming. Most grammars supplied
as examples have been commented in our publications.
A grammar producing a famous Kathak
number
tihai composed by Pandit Birju Maharaj will be
found in "-gr.12345678". More
tihais have been implemented in "-gr.ShapesInRhythm". If you need to play
lahras (cyclic melodic phrases) to practise Indian percussions, use "-da.lahras".
Indian raga music is also a good
candidate for composition/improvisation models based on grammars and automata.
The subtleties of
alankara and
gamaka may be rendered by performance parameters. Examples are still
lacking since performance controls have been introduced
recently. When Kumar S. Subramanian spent a few days in Delhi, he started
composing items related to South Indian tunes. I have taken the liberty to
insert some of his work in the example folder ("-gr.trial.mohanam" and "-gr.kss2").
We recently came to know that a team
located in Mumbai (= Bombay) had devised an excellent method for the synthesis
of tabla sounds. We hope to make it accessible to BP2
users shortly.